

To Train or Not to Train
The case for and against post-training for application layer companies
I’m Tanay Jaipuria, a partner at Wing and this is a weekly newsletter about the business of the technology industry. To receive Tanay’s Newsletter in your inbox, subscribe here for free:
Hi friends,
A few weeks ago, I wrote about how AI application companies are increasingly going full-stack, integrating down into the model layer or up into the service layer. Since then, there’s been a lot of discussion around the pros and cons of going into the model layer and when the right time is, which will be the focus of today’s piece.
To be clear, this discussion is in the context of application-layer companies, not frontier labs. Very few of these companies are pre-training from scratch. Instead, most are post-training and RL on strong open-weights bases.
In this piece, I’ll cover:
The training spectrum
The case for doing it
The case against doing it
When it makes sense, and the new infrastructure that’s lowering the bar
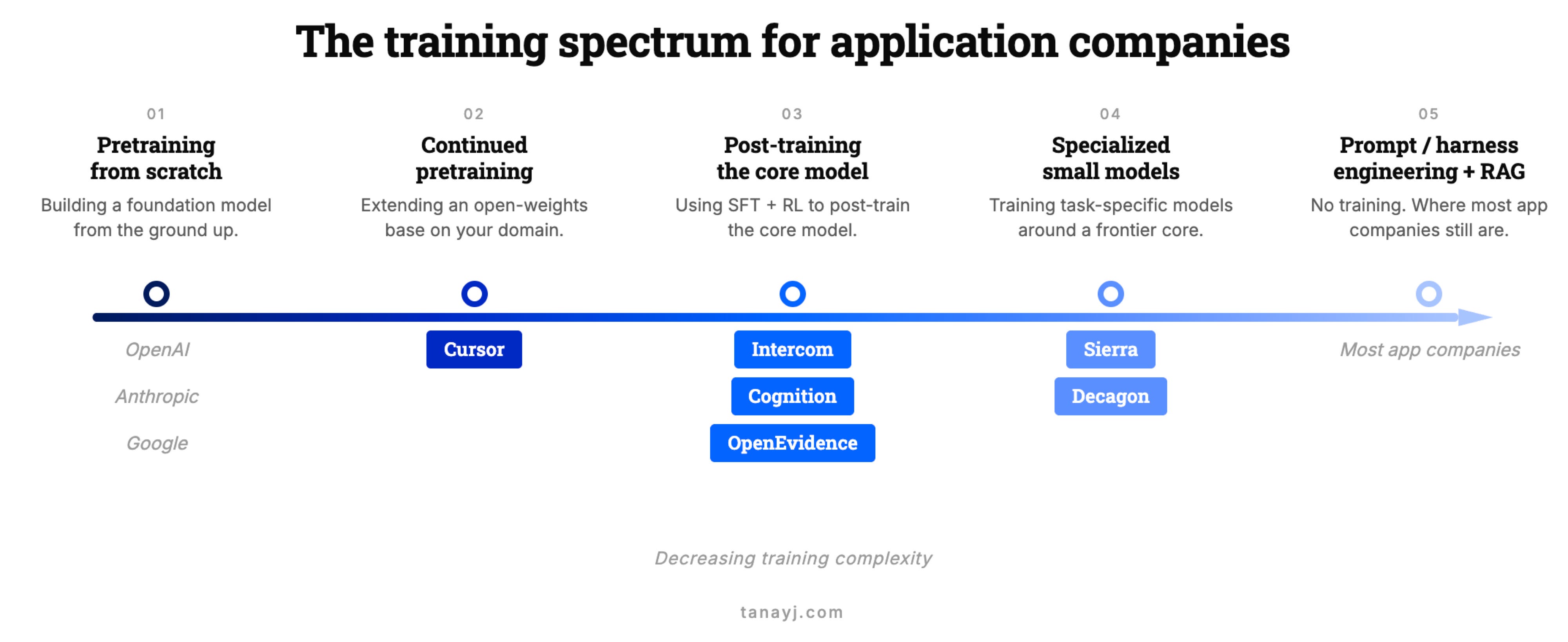
I. The training spectrum
“Training your own model” gets used to describe wildly different commitments.
At the extreme end, there’s prompt engineering, RAG and harness engineering, which isn’t training in any form. A step up, fine-tuning a small model. Further up, supervised fine-tuning or RL on a strong open-weights base as the primary model in the system. Further still, continued pre-training on top of an open-weights model. At the far end, pre-training from scratch.
For application companies, basically nobody is at the far end but as you go right from there, you see examples at the different points. Cursor’s Composer 2 builds on Kimi K2.5. Intercom’s Fin Apex 1.0 sits on an undisclosed open-weights base. Cognition’s SWE-1.5 is, in their words, “end-to-end RL on real task environments using our custom Cascade agent harness on top of a leading open-source base model.”
As Intercom’s CEO put it, pre-training has become “kind of a commodity” and the action is in post-training. And so most of this piece will be in the context of post-training rather than pre-training.
II. The case for training
In my view there are three real reasons to invest in post-training.
1. Unit economics and latency
Once you’re at scale, API calls add up. A smaller specialized model that runs cheaper and returns in 200ms can beat a frontier call that takes 2 seconds and costs 10x as much.
Intercom’s Fin Apex 1.0 reportedly runs at roughly one-fifth the cost of frontier models, responds 0.6 seconds faster than the next-fastest competitor, and resolves customer issues at a higher rate. At the scale of a company like Intercome doing ~2M conversations per week, that gap in latency and unit economics is meaningful.
There’s a related destiny argument: if your unit economics depend on one frontier API, you’re exposed to pricing changes, rate limits, and the provider showing up in your category. No one has felt this more than Cursor, which despite tremendous success and usage, reportedly has -21% gross margins, and has found it difficult to compete with Claude Code when Anthropic’s limits supports thousands of dollars of equivalent compute in their $200 max plan.
2. Differentiation through proprietary data
If everyone is calling the same frontier API, where’s your edge? Increasingly, it has to come from the traces you’ve accumulated.
Cursor sees which completions get accepted and rejected. Intercom has billions of customer-service interactions. OpenEvidence has the queries and citations of 40% of US physicians and trained a domain-specialized model which captured data from peer‑reviewed medical literature via their partnerships. That’s proprietary training data and the best way to put it to work is through training or post-training.
In some ways, the real vaue of the application layer is that they get the best telemetry on the real use cases of their customer base, far better than any off-the-shelf evals can measure.
And by leveraging those to post-train models allows them to actually improve performance for their users while also getting the latency and unit economics benefits outlined above.
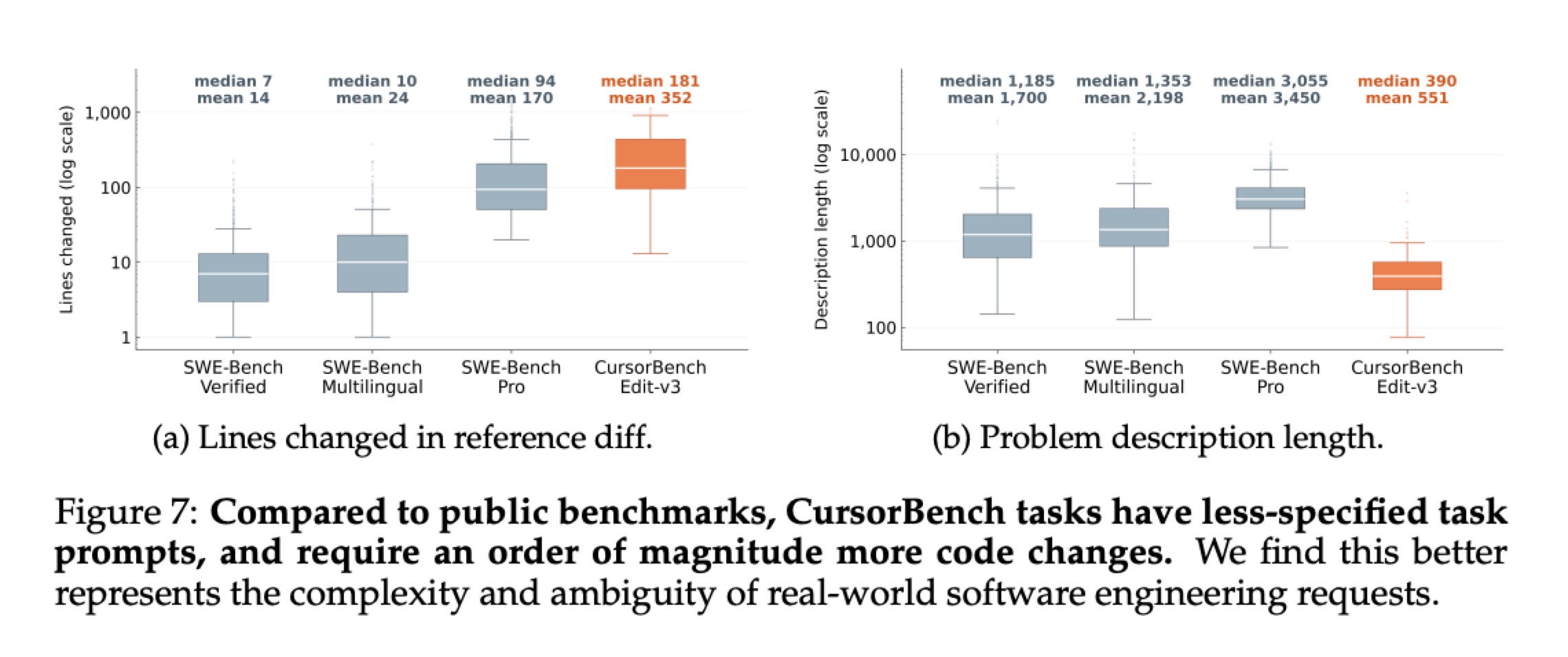
For example, Cursor’s Composer 2 was in part optimized on their internal eval Cursor-bench which they created based on their real traces. They felt this benchmark was more representative of the real work developers were doing within their platform than the publicly available benchmarks.
3. Specialized models for the parts frontier labs don’t prioritize
Most application companies aren’t just training one big custom model to replace the frontier. They’re running systems of small specialized models, each fine-tuned for one part of the pipeline that the frontier labs don’t optimize for.
Decagon talks about this: smaller fine-tuned models for query rewriting, routing, and intent classification, with a frontier model only where it’s actually needed. Sierra trained custom search models (Linnaeus and Darwin) inside a constellation that still uses OpenAI, Anthropic as core models. Cognition has SWE-grep for context, SWE-check for bug detection, SWE-1.5 for the main agent.
Most of the value is in the boring parts of the pipeline (voice activity detection, query reformulation, retrieval ranking, tool selection). None of these need a frontier-grade reasoner. All of them benefit from being faster, cheaper, and tuned to your specific data.
This is a great way to step into fine-tuning and post-training for many companies: train where the frontier underserves you and keep using the frontier where it doesn’t.
III. The case against
The biggest reason to be careful: your post-trained model may not survive the next base-model release from the lab. The labs are now releasing new models faster than ever, because the labs themselves are using their own models to build the next ones.
Anthropic’s Dario Amodei has said that 70-90% of the code for new Claude models is now written by Claude itself. OpenAI was even more direct in their GPT-5.3-Codex announcement (now 0.2 generations behind :)):
“GPT-5.3-Codex is our first model that was instrumental in creating itself. The Codex team used early versions to debug its own training, manage its own deployment, and diagnose test results.”
What this means: model releases that used to take months are now arriving weeks apart. OpenAI shipped GPT-5, 5.2, 5.3, 5.4, and 5.5 within months.
For an app company, that’s the biggest risk. A lot of fine-tuning wins from 2022-2024 dissolved when GPT-4 and Claude 3.5 came out, and the cycle is faster now.
That’s why in general, it’s much safer to post-train or fine-tune specialized models that work in a system of models rather than the core reasoning model for frontier tasks since the cost and latency benefits of those are more likely to survive even as base models improve.
There are other costs to consider as well namely that post-training talent is scarce and expensive. The opportunity cost of the talent and capital used to post-train models could be better deployed or leveraged in other aspects of the product and company.
IV. When to do it
One useful proxy is to train when you have enough proprietary traces to make a small specialized model meaningfully better than the frontier on a specific part of your pipeline.
I should note that the bar to start is also lower than it was a year ago, because a new infrastructure layer has shown up to support post-training in different forms.
Tinker from Thinking Machine Labs is a managed post-training API. They handle distributed training and LoRA infrastructure while you bring data, algorithms, and environments. As Andrej Karpathy’s noted: it lets users keep about 90% of the algorithmic control while removing about 90% of the infrastructure pain.
Prime Intellect’s Lab is similar, hosted RL training plus an open Environments Hub with hundreds of community-built RL environments.
Applied Compute, founded by ex-OpenAI researchers, is a more white-glove version, post-training on enterprise proprietary data using RL environments and is one of many companies offering some version of RL-as-a-service.
Vendors such as Mercor, Surge AI, Fleet and others sell custom expert-authored RL environments
Lastly, the Chinese labs and their open-source base models that are competitive with the frontier closed source models serve as a starting-off point for many.
I do think the improved infrastructure has meant that even small teams of 10-20 can now post-train if they want to. But one mantra I like that still holds true for most application layer companies is “no GPUs before PMF.” If you don’t have the product or the traces yet, training a model to do that product is premature.
Post-training should be part of the conversation once a company is either rapidly scaling and has collected enough traces or at least has PMF and feels underserved by the frontier in some specialized aspects of their product which they feel the base model can fix.
Closing Thoughts

The companies integrating down into the model layer (Cursor, Intercom, Sierra, Decagon, Cognition, OpenEvidence) aren’t doing it because they like training models. They’re doing it because at their scale, with their traces, the economics and differentiation arguments finally pencil out. And almost all of them are doing it as post-training, not pretraining from scratch.
For most app companies earlier in their lifecycle, the honest answer in 2026 is: not yet, but start setting up to. Build the data collection now (traces, evals). Start with one small specialized model in a boring part of your pipeline rather than trying to replace the frontier on the main reasoning call.
The durable training investment is the data and environments you accumulate, which let you keep producing better models as the bases under you keep improving. And remember, those base models are improving faster than ever.
If you’re working on an AI application or thinking about this tradeoff, feel free to reach out at tanay at wing.vc.