



The Plummeting Cost of Intelligence
On smaller models, on-device inference and the path to zero cost intelligence
This is a weekly newsletter about the business of the technology industry. To receive Tanay’s Newsletter in your inbox, subscribe here for free:
Hi friends,
While foundation models are often perceived as costly and inference bills are rising, the reality is that the cost of intelligence is in free fall—and this trend shows no signs of slowing. Elad Gil shared this chart on the cost of GPT-4 equivalent intelligence from Open AI, which has fallen 240x in the last 18 months, from $180/million tokens to less than $1.

There are a number of factors driving this continued decline in the cost of intelligence, which if played out fully, can see a world where for all practical purposes, the cost of intelligence via models (for the vast majority of use cases) will tend to zero.
In this piece, we'll explore the key factors contributing to the declining cost of intelligence.
1. Competition and Market Forces
As more models, including open source ones from Meta, have caught up in performance to GPT-4, the resulting competition, both between various model developers and inference providers, has pushed down costs.
The rate sheet below shows the variety of provider options users have to run Llama 3.1, for example:

Similarly, for a given level of model quality, users have multiple options, which results in pricing pressure and some degree of convergence in prices, as in the chart below.
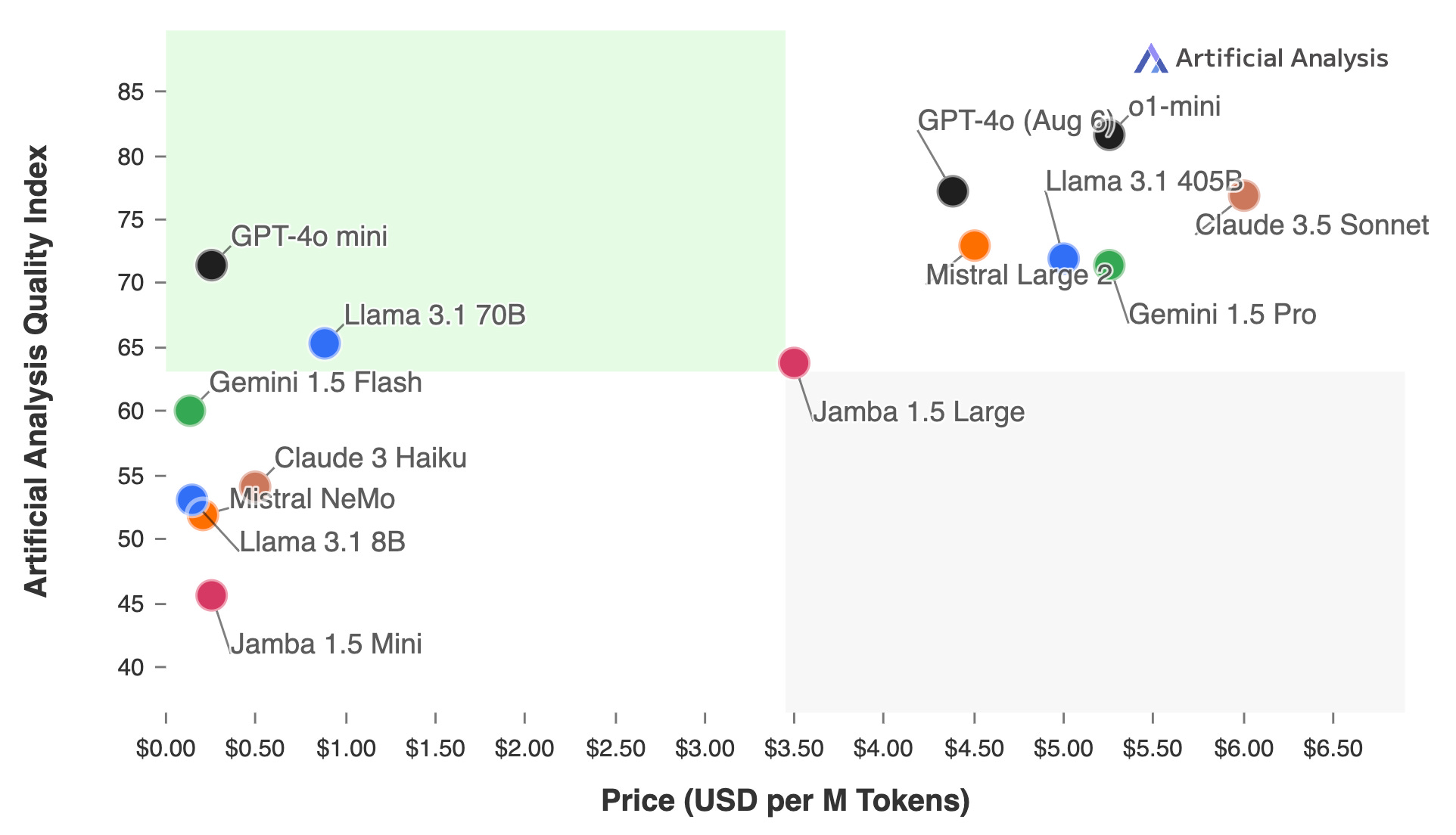
Even with OpenAI’s recently released O1, if history is any guide, other models will catch up, and pricing will decline (although given the increase compute use at inference time may use up more tokens/be more expensive for a little while).
2. Improving Efficiency in Compute
Obviously, just market forces isn’t enough to lower prices by itself. Optimizations at both the hardware and infrastructure layers have reduced the cost of running inference, allowing companies to pass these savings on to customers.
On one end, we’re seeing significant innovation at the hardware layer, whether from specialized chips / ASICs such as Inferentia by Amazon or players such as Groq, which are providing alternatives and while still nascent showing what is possible price and speed wise.
Amazon cites that their Inferentia instances deliver up to 2.3x higher throughput and up to 70% lower cost per inference than comparable Amazon EC2 instances.
Similarly, as inference workloads are starting to scale up, and more talent is building in AI, we’re getting better at utilizing GPUs more effectively, and getting more economies of scale and lower inference costs through optimizations at the software layer as well.
If you don’t yet receive Tanay's newsletter in your email inbox, please join the 9,000+ subscribers who do:
3. The Rise of Smaller, Smarter Models
Another key reason for the declining cost of AI is the improvement in performance for a given level of model size, and smaller models getting smarter and smarter over time.
One great example of this is that Meta’s Llama 3 8B model basically performs on par or better than their Llama 2 70B model which was released a year earlier. So within a year, we got a model almost 1/10th the parameter size which had the same performance. Techniques like distillation (using the outputs of larger models to fine-tune smaller, task-specific models) and quantization will continue to enable smaller models to become even more capable.
An interesting note here is that Llama 3.1 405B’s license allows for using its output as data for fine-tuning other models, which further enables this trend.
If you use the Llama Materials or any outputs or results of the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is distributed or made available, you shall also include “Llama” at the beginning of any such AI model name.
4. New Model Architectures driving efficiency
There’s also a push toward entirely new model architectures that promise to make AI even more efficient. While transformer models still dominate, new architectures such as state space models are emerging as strong contenders with companies such as Cartesia leading the way.
These new approaches can be faster, more efficient, and require less compute power to achieve comparable performance. As more progress is made on them, they may become another avenue for small, highly efficient and performant models, which will have lower inference costs relative to their performance, further driving down the cost of intelligence.
As an example, some of the Mamba class of models in the 1.5B-3B parameter range, outperform the leading transformer based models of that size.
5. On-Device Inference
The future of AI isn’t just about cloud-based models—it’s increasingly about running AI directly on end-user devices. Apple has already announced two proprietary 3B parameter models that will run locally as part of their Apple Intelligence launch: one language model and one diffusion model (more details). While these models will initially only be used by Siri and other first-party apps and are not yet available to developers, it seems likely that they will be made available in the future.
Apple’s benchmarks show that while on-device models can’t be used for all queries, users tend to prefer them for many queries, even compared to larger models, as below.

In addition, as the chips on laptops and phones continue to get more powerful, coupled with models getting smaller and smarter as discussed above, a larger and larger fraction of the most commonly used needs for intelligence can be handled with models running locally. For example, companies such as ollama already allow running popular models such as Llama 3-8B locally on laptops today.
Besides the privacy and latency benefits of that for users, that will also have huge cost implications, in that intelligence will truly be ~zero cost in that case.
Closing Thoughts
As the cost of AI continues to drop, we’ll see a wave of new applications and industries embracing these technologies. My advice to founders and builders is not to focus too much on inference costs (as long as they aren’t causing significant cash burn) and to avoid over-optimizing too early, as these costs are dropping rapidly.
Instead, I encourage founders and builders to think about what use cases or additional features don’t seem feasible yet, but are potentially unlocked as the cost of intelligence declines to 1/10th or 1/100th of the current price, since we’ll likely get there sooner than most think.
If you’re building a company that helps drive down these inference costs across any layer or leverages a future of low-cost intelligence to solve problems for end users, I’d love to hear from you at tanay at wing.vc
There are probably two reasons why that the cost of intelligence is dropping. First, data via webscraping is essentially free. Second, the cost of capital of the big models is effectively zero given that the investors backing the models have a different set of incentives. This is what has worried me about VCs mixing LP dollars with the corporates. Not to mention Meta is trying to undermine all the private models and has an infinite war chest to out complete everyone at a game of chicken.. What happens when the data for training is no longer free because the owners of data start charging a fee for access?
In a world where intelligence is nearly free, the value of human creativity and strategic thinking will skyrocket.