



Understanding Twitter's Algorithm
How Twitter's ranking works and how to game it
This is a weekly newsletter about the business of the technology industry. To receive Tanay’s Newsletter in your inbox, subscribe here for free:
Hi friends,
Many years ago, I worked on the Facebook News Feed algorithm, where we worked towards making people’s News Feeds more relevant and engaging to them.
Over the years, these algorithms have only grown in importance as all of Facebook, Instagram, TikTok, and Twitter have adopted recommendation-powered algorithms1 as their default “home” surface, leading to them becoming how most people all over the world consume a lot of their content.
Prior to this recent AI wave and arguably still to this day, recommendation algorithms are likely the most used and important form of AI that consumers interact with regularly.
Twitter open-sourced their algorithm earlier last week, and I had a chance to look over it. While they didn’t release the training data that their models were trained on and so once can’t reconstruct it fully, the open-sourced code gives us a sense of how everything works and what they value in the ranking.
Today, I’ll go through how the algorithm works and a few interesting findings from their algorithm.
The Algorithm Explained
At a high level, here is how Twitter’s algorithm works:

Retrieval: Twitter’s algorithm fetches the ~1500 “best” tweets total for a given user in a given session across multiple sources.
Ranking: It then ranks those tweets using a machine-learning model
Filtering: It then applies a few heuristics and filters to remove things you’ve blocked/muted/seen
Mixing: Lastly, it mixes in a few promoted tweets and other Twitter units (that aren’t organic tweets).
Now, let’s dig in a bit more.
1. Retrieval
A natural question might be, how does Twitter come up with that initial list of tweets?
It uses two sources: (1) in-network sources (the top tweets from people you follow) and (2) out-of-network sources to try to generate an initial list of ~1500 tweets.
(1) In-network sources: The universe of in-network tweets is basically all the tweets from all the people you follow that you’ve not seen, which applies some light ranking (detailed later) to determine which are the top ones. On average, about 750 of the list that Twitter comes up with is from in-network sources.
(2) Out-of-network sources: To get the very best of Twitter from the people you don’t follow, which as one can imagine can be 100s of millions of tweets, Twitter does two things:
Social graph: Generate tweet recommendations based on Tweets popular in your social graph (i.e., what do people who like similar tweets to you engage with). About ~30% of the out-of-network source tweets come from this source.
Topic embeddings: Generate tweet recommendations based on the topics you tend to enjoy, based on mapping all users and tweets into clusters/communities using embeddings. Twitter has clustered things into 145K communities, with some of the larger ones below. About 70% of the out-of-network source tweets come from this source, and over time, I expect Twitter to move towards this approach more over the social graph approach for out-of-network sources.

2. Ranking
So now that Twitter has these 1500 tweets, how is it then ranking these tweets so it decides what order to show them to you (and also what ranking did it use to whittle it down to 1500?)
One way to think about the ranking problem is that given some objective function, score each of the tweets against that function and order them according to that score.
For a social network, an objective function usually takes the form of some sort of engagement, and that’s exactly how Twitter works.
Basically, given a user whose timeline it is loading, and given a tweet X, Twitter tries to predict the likelihood that the user will take actions such as like, comment on, retweet, etc on the tweet.
It then assigns a weight to these actions and multiplies the prediction of the likelihood of the action with its weight across all actions to get an overall score for the tweet for the specific user, as below
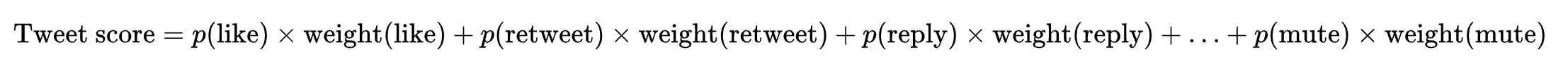
The full list of actions that the model is making predictions about and the weight applied are below:

Remember, these are predictions about a given user for a given tweet and not the actual values of a given tweet. It will be based on a few things:
User-level: Who this user is, and what they tend to engage with, how often do they tend to engage, etc.
Tweet-level: Factors about the tweet itself (actual engagement data on it, etc)
User-relationship: Prior history between the user whose timeline is being ranked and the user who posted the tweet being ranked — does the user tend to like/reply to a lot of that user’s tweets, etc.
I’ll touch on some tactical learnings about these further on.
3. Filtering
Once all the tweets are scored and ordered, we now have ~1500 tweets ordered based on the score determined as above. The last stage is the filtering stage, where basically some post-processing is done to the list.
It involves a mix of things to exclude tweets as well as other things to downrank certain tweets, such as:
Visibility Filtering: removing tweets from people you have blocked and muted
Author diversity: Make sure you don’t have too many tweets from one user too close together in your list
Content balance: Balancing in-network and out-of-network (they really shouldn’t be doing this in my opinion other than to increase in-network tweets)
After this stage, you have say ~1000-1200 ordered tweets ready to be shown to the user.
4. Mixing
The mixing stage is honestly not very interesting. All it does is that it in between these organic tweets Twitter will throw in certain ads and other non-organic tweets based on rules such as the gap between two ads should be 4 tweets, etc.
After this stage, you have the full list of tweets in the order it should be shown to the user, including the ads. In essence, you now have the full timeline you can just display or “print” for the user.
How to get your tweets to rank highly?
The bulk of the magic of ranking is determining the predictions/likelihood a given user will interact with a given tweet. As touched on above, these scores are based on: factors about the user, factors about the tweet and factors about the users relationship with the poster of the tweet.
As a poster, you can’t control anything about the user who is potentially seeing your tweet. But you can control aspects of the tweet and aspects about you. So let’s discuss those.
A. Tweet Factors
Post Images and Videos: They receive a 2x boost
Post in the same language as your followers: Tweets in a different language from them get penalized by 90%
Post about something that’s trending: That receives a 1.1x boost
Don’t post multiple hashtags: That gets penalized by 40%
Don’t post misspellings/unknown words: That gets penalized by 95%

B. Tweet Engagement Factors
The more engagement your tweet has, the more likely the model will predict that a given user is more likely to engage with it. While in the ranking model predicting whether a user takes action more weight is given to replies, in the actual tweet-level data about the tweet, more weight seems to be given to likes. This is a bit strange and I’m not too sure of the rationale for this.
Each like gets a boost of 30
Each retweet gets a boost of 20
Each reply gets a boost of 1

Similarly, avoiding negative engagement (mutes on the tweet/user, reports/blocks, unfollows) on your tweet since those lower the tweet level score.
Lastly, as time goes on, a tweet’s score decays over time, leading to lower predictions and less likely for it to be shown. Specifically: tweets have a half-life of 6 hours, meaning that every 6 hours, the base score decreases by 50%.

C. User Factors
Lastly, there are also certain actions you can take at the user level so that your tweets rank highly:
Subscribe to Twitter Blue: Blue users get boosted by 4x for people who follow them and by 2x for people who don’t follow them

Don’t follow too many more people than follow you: You get penalized if your followers/following ratio is very low.
Be aware that all your actions are going into calculating a TweepCred: Twitter has something like Google’s PageRank for every user known as Tweepcred, which assigns a score of 0 to 100 for every user. If your score is high, its more likely more of your tweets are eligible to show. While some of the details were missing, it takes into account age, safety status, followers and following, and past engagement data, especially things like if a lot of your tweets were getting reported or not.
Thanks for reading! If you liked this post, give it a heart up above to help others find it or share it with your friends.
If you have any comments or thoughts, feel free to tweet at me.
If you’re not a subscriber, you can subscribe for free below. I write about things related to technology and business once a week on Mondays.
Until quite recently, Facebook, Instagram and Twitter only showed (non ad) content from people you explicitly followed in your home timeline, rather than from the whole user base.
I really loved the way you presented the technical aspects with the customer engagement section.
Inspiring, thank you so much for this!