

Understanding the Modern Data Stack
Hi friends,
You might have heard the term “Modern Data Stack” being thrown around a lot. This week, I’m going to go over what that tends to look like today.
This will be more of a 101/102 type explainer than I typically write, but I hope that a portion of you enjoy it. In future posts over the coming month, I’ll build on this and discuss the opportunities and implications of the move to the modern data stack.
What is the modern data stack?
Simply put, the modern data stack refers to a suite of products used for data integration and analysis by the more technology-forward companies. One of the key characteristics which make the tools as part of the stack “modern” is that they are all cloud-native.
Compared to legacy stacks, this tends to offer a few benefits:
lower barriers to set up and deploy
easier to scale up as needed
more operationally focused than IT focused
Now, let’s get to the components of the modern data stack, as visualized below.
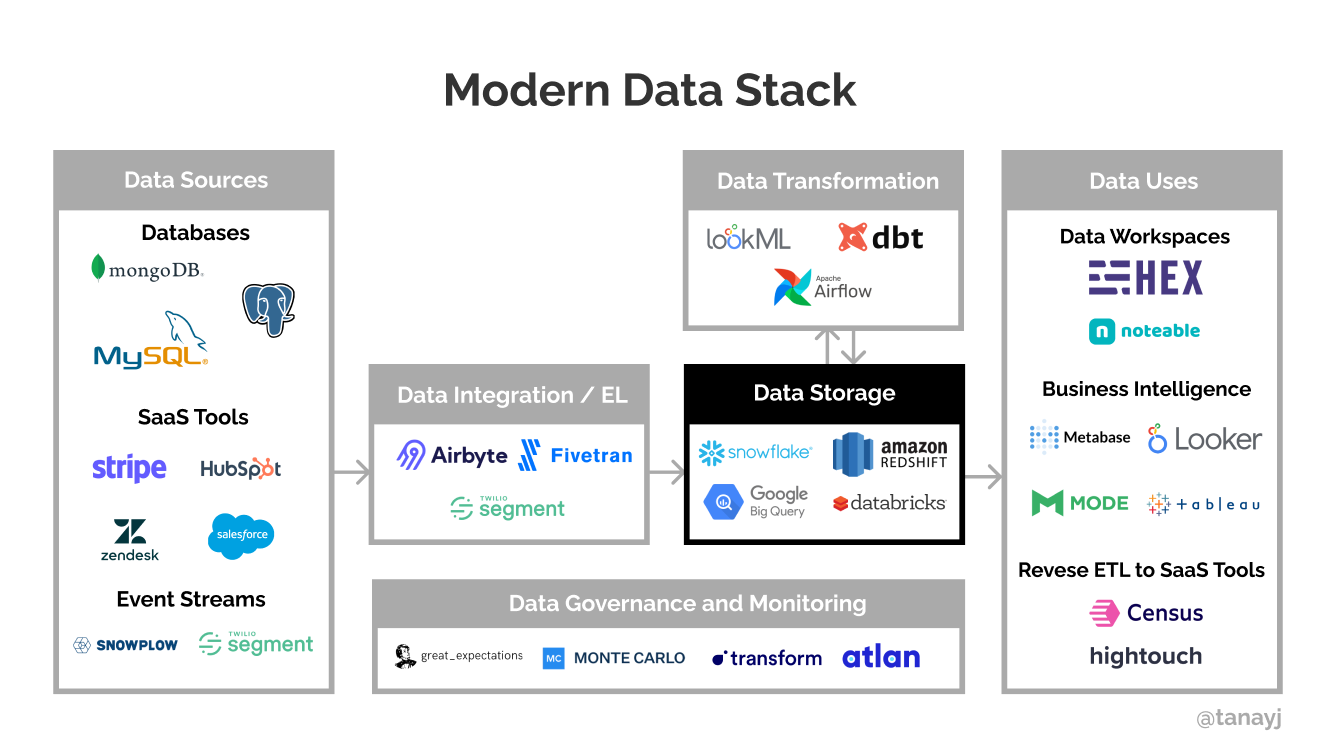
Data sources
Every company collects or generates a lot of data from a multitude of sources.
Databases: Typically, companies use a database to store key information which powers their product. This includes information about users and the data the users typically generate in the product. For example, TikTok may have one database for all the users that are registered, another one consisting of all the videos that are uploaded, etc. Some commonly used databases include Postgres Mysql and Mongo.
SaaS Products: Companies today use a myriad of SaaS products to run their business, many of which contain key data such as billing/subscription information (Stripe), customer information (Salesforce), support tickets (Zendesk), etc.
Event streams: It’s pretty common these days to log every little interaction about users as events that can be used for analytical purposes. These include measuring clicks to various things in the website/app. For example, an eCommerce store may fire events every time any product is clicked on or when any product is added to the cart. These can then be used to analyze things such as what are the most popular products in terms of views cut by various user personas. Commonly used products include Segment and Snowplow.

Data integration
So what happens with all this data? The goal is to bring it over to a centralized place, which for most companies today is a cloud data warehouse.
The way that data makes its way to a centralized warehouse is through a process of extracting the data from the various tools and databases and loading them into the warehouse as-is. One thing to note is that the traditional approach used to be something known as ETL, where data was extracted and transformed before being loaded in a centralized location.
Now, typically, the process is ELT, where data is extracted and loaded into the warehouse, and transformed directly into the warehouse.
This is done using several SaaS tools that have popped up which now provide 100+ connectors to easily extract and load data from various data sources into the most commonly used data warehouse/data lakes. The most popular ones are Fivetran and the open-source Airbyte as well as Segment which was mentioned above and is also used for this in some cases. Portable is another which focuses on the long-tail of connectors, and over time has built up a wide repository of them.
These tools usually schedule batch jobs to load the data into the warehouse, while there are some other solutions such as Apache Kafka (or Confluent’s managed version) or Snowpipe which can be used to stream data directly into the cloud warehouse for more real-time use cases.

Data Storage and Querying
Using the tools above, the data is stored in a centralized place, typically a cloud data warehouse, although data lakes can also be used. While the differences between the two are out of scope for this piece, typically data lakes have cheaper storage and so tend to be used for storing raw data in a mix of formats (unstructured, semi-structured, etc).
In addition to storage, these cloud warehouses can be directly queried and used for analytics purposes, and they serve as the central component of the data stack.
The most popular cloud warehouses are Snowflake, Google’s bigQuery, and Amazon Redshift, with a popular data lake option being Databricks.

Data Transformation
The data is then transformed directly in the warehouse itself to make it easier and more useful for consumption by data scientists and business users. This generally involves modeling the data and creating some analytics-specific tables which are aggregates or structured versions of some of the other tables in the warehouse.
Once created, these tables can be used by all the users of data for analytics and other purposes.
dbt is one of the most popular tools used for this which allows doing this with a mo. Other options include the use of Apache Airflow or LookML as well as Databrick’s Delta Live tables.

Data Governance and Monitoring
We’re almost ready to use our data, but before we get to that, let’s quickly touch on data governance and monitoring.
This involves several functions such as:
Testing and monitoring pipelines so that errors or issues are caught and can be addressed. While dbt does support testing, Monte Carlo and Great Expectations are two commonly used products in this space of data observability.
A metrics layer so commonly used metrics (e.g. monthly active users, ARR, churn) are defined in a standard way in code and the same definitions are used across the organization. Transform is one of the companies in this emerging space.
Data cataloging/documentation and discovery so that people in the organization can discover the right tables for their use. Atlan is one of the companies in this space, and there are several open-source solutions: Amundsen (Lyft), Datahub (LinkedIn), and Metacat (Netflix) among others.
Data privacy and access controls so that companies can easily control which employees have access to what data. Atlan is again commonly used for this.

Data Uses
At a high level, there are three broad uses of the data that I want to touch on, aside from machine learning uses, which are out of scope for this piece.
I. Analytics and Collaboration among Data Analysts and Scientists
For pulling data or performing one-off queries, data analysts can write SQL and directly query the warehouse (Example).
However, several products make it easier for these analysts and scientists to query, visualize and collaborate on data and create dashboards as needed. Some of them include Noteable and Hex.
II. Business Intelligence
Sometimes, business users who may not be as data-savvy may want to use the data to dig into or perform ad-hoc analyses. This sphere is known as business intelligence, allowing users to explore and drill down into data or replicate SQL visually. Some of the popular tools include Looker, Tableau, Mode, and the open-source Metabase.
III. Data in key systems of records
For many operational use cases such as customer support, marketing, sales, etc, one of the valuable uses of the data is to have it available in the primary tool they spend the majority of their day in such as Salesforce or Zendesk, or Hubspot.
As you may recall, the data from these systems were put into the warehouse. But now the aggregate of that data can be combined and sent back to the tools in essence enriching the data available in that product.
To address this use case, there are “Reverse ETL” tools such as Hightouch and Census which essentially sync data back to the SaaS tools these business users are spending time in.
As an example, by using these tools to sync data such as product usage data into Salesforce, a sales rep can see prospective customers’ product usage data and activity to determine which customers to prioritize and talking points to use while trying to upsell specific ones to a paid plan.

That’s all for this piece on the modern data stack. In the future, I’ll outline the areas of opportunity and some of the implications of more and more organizations moving to a modern data stack that looks more or less like this.
Thanks for reading! If you liked this post, give it a heart up above to help others find it or share it with your friends.
If you have any comments or thoughts, feel free to tweet at me.
If you’re not a subscriber, you can subscribe for free below. I write about things related to technology and business weekly on Mondays.
Great overview!
ta