

Towards Continual Learning
The quests to make AI agents learn from experience, across weights, context, and harnesses.
I’m Tanay Jaipuria, a partner at Wing and this is a weekly newsletter about the business of the technology industry. To receive Tanay’s Newsletter in your inbox, subscribe here for free:
Hi friends,
AI has made a lot of progress, but even the best agents don’t feel quite like coworkers yet in the way that humans do.

Dwarkesh Patel made the case last year in a piece arguing AGI isn’t close, and the bottleneck he kept landing on was the idea of continual learning:
But the fundamental problem is that LLMs don’t get better over time the way a human would. The lack of continual learning is a huge huge problem. The LLM baseline at many tasks might be higher than an average human’s. But there’s no way to give a model high level feedback. You’re stuck with the abilities you get out of the box. You can keep messing around with the system prompt. In practice this just doesn’t produce anything even close to the kind of learning and improvement that human employees experience.
The reason humans are so useful is not mainly their raw intelligence. It’s their ability to build up context, interrogate their own failures, and pick up small improvements and efficiencies as they practice a task.
Models today learn during training, then the weights freeze, and from then on they don’t get better at your job no matter how many times they do it (absent skill files and memories).
Yash Patil, who runs Applied Compute, frames the same gap in Apoorv Agrawal’s class in terms of how “cheaply” a human learns:
If you go and burn your hands on the stove, you just need to do that once and then you know the stove is hot and not to put your hand on the stove. These models today are not really like that.
A person updates from a single sparse signal. A model needs the lesson spelled out every session.
So the question then becomes how you let a system actually learn from doing the work. And there are basically two places you can do it: in the weights, or in everything around the weights.1
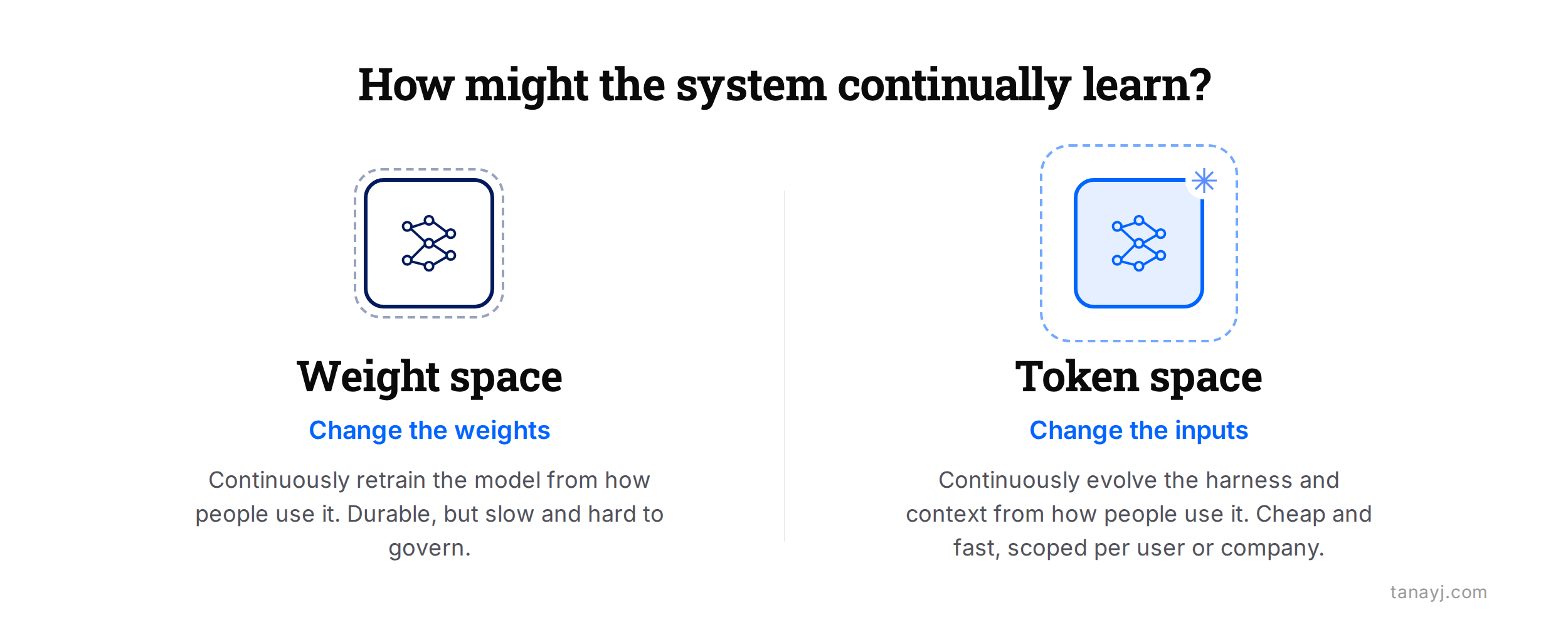
Weight space
The first place to potentially solve continual learning is the weights themselves. The most common version: take the signal from real usage at some interval and post-train on it with fine-tuning or RL, so that the model learns / improves over time based on actual usage.
Two research directions push further than this. One is test-time training, where the model updates its own weights while it runs, adapting to the specific input in front of it instead of staying frozen between training runs. The other somewhat adjacent idea is meta-learning, where instead of training the model on the right answers, you train it on how to find or discover them, so it learns to reason and search its way to an answer rather than memorize one. Technically, this doesn’t need a weight change since it’s a training time technique, but it could improve the ability of the model to feel like it adapts upon use better.
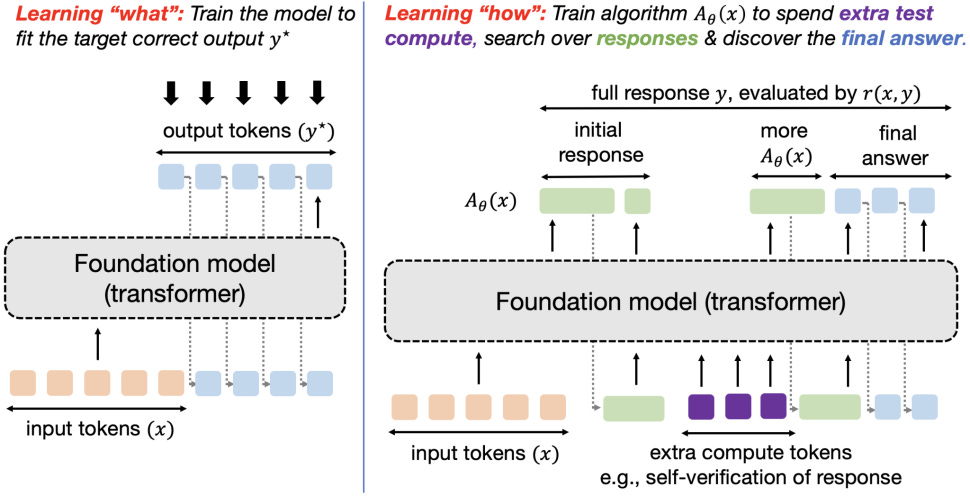
Getting to true continual learning through weight updates is challenging for multiple reasons:
One is catastrophic forgetting. Try to fine-tune a model on something new and it tends to quietly get worse at things it already knew. In the context of continual learning, the risk would be you teach it this month’s workflow and it loses something it was fine at last month. Keeping a model both stable and plastic at the same time is an open research problem which is why you can’t simply just fine-tune on every interaction.
Two is the practicality of learning continuously. Sure, you could maybe post-train a model every month or every week. Could you do it on every interaction? Would it be on a company basis or an organization basis, or could you do it on a per-person basis, per-person interaction? In an ideal sense, that is, in some ways, what continual learning might be: every person has a set of weights that are constantly changing and adapting based on how they are interacting with that model or the harness around that model.
Satya Nadella has a framing around this where perhaps all the company tacit knowledge lies in a LoRA layer in some way:
Clearly it resides in people’s heads and it’s the classic know-how that accrues and compounds. I think it’ll also reside and compound as weights in some LoRA layer that is unique to your company. I feel like the new intellectual property at Eli Lilly or at Microsoft or at Stripe at some point can be also, besides all the humans, besides all the other artifacts we have, I think we’ll also say, “Oh, they are in some embedding.”
One downside to continual learning in weight space is permissioning and governance. You can gate what context a given person sees pretty easily. But once something is trained into a model, it’s just in there, and “this person shouldn’t have learned that” is a much harder thing to enforce. Similarly, models could diverge in unintended ways and regress, and so being able to monitor and govern to do things like roll back to a stable checkpoint when an update makes things worse and what data changed which weights becomes important.
Continual learning in weight space is very much an ongoing research area, with Cursor’s online RL perhaps one good example in production, where the model is improving from the online production usage every 5 hours.

This is still a relatively basic form of continued learning, in that it’s still one model that every user and every company is using. It’s not being personalized in some ways, but at least it is continuously improving based on production traffic.
We serve model checkpoints to production, observe user responses, and aggregate those responses as reward signals. This approach lets us ship an improved version of Composer behind Auto as often as every five hours.
Let’s now talk about another “technique” to continually learn.
Token space
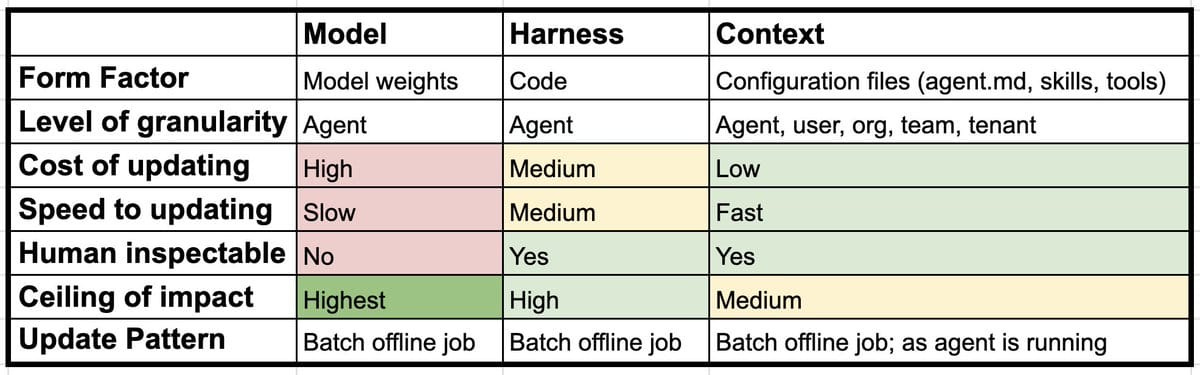
Token space essentially means everything around the model. You keep the weights frozen and you change what reaches them. On a practical level, you can think of this as having two layers, as Harrison Chase splits it into, the harness (the code, tools, and scaffolding that drive the agent) and the context (the instructions, skills, and memory that configure it), or combine both to think of it as token space or the stuff in and around the model.
Context is more straight forward. An agent keeps a running memory, rewrites its own instructions as it goes or creates new skills, and runs over yesterday’s logs overnight to fold what worked into its config for tomorrow. OpenClaw calls that overnight pass “dreaming”. The good thing about learning at this layer is that it can be easily scoped or personalized: one evolving context per company, per team, or per user, all riding on the same base model.
The idea of a continually improving harness is perhaps more interesting. There’s an idea called meta-harness that does exactly this. You keep a filesystem of every past run, and a coding agent reads it and proposes new harness code, new tools, new prompts, with the goal of maximizing an eval score. You run that harness around a frozen model against a set of tasks, score it, and store everything (the proposed code, the reasoning traces, the score) back to the filesystem so the next proposal is smarter. It’s basically RL, except the thing getting optimized is the code around the model, not the weights inside it.

In some ways, learning in token space can be easier and cheaper and have better governance. But it often relies on storing the right information in skills, memory files, etc and the problem somewhat shifts to making sure the model retrieves it at the right step.
Harrison Chase at Langchain summarizes the various tradeoffs to learning at each level. At a practical level, getting to some form of continual learning that feels solved will involve learning at all three layers.
Companies Tackling Continual Learning
A lot of companies are trying to tackle continual learning now other than of course the frontier labs themselves. They fall into three rough camps based on their approach.
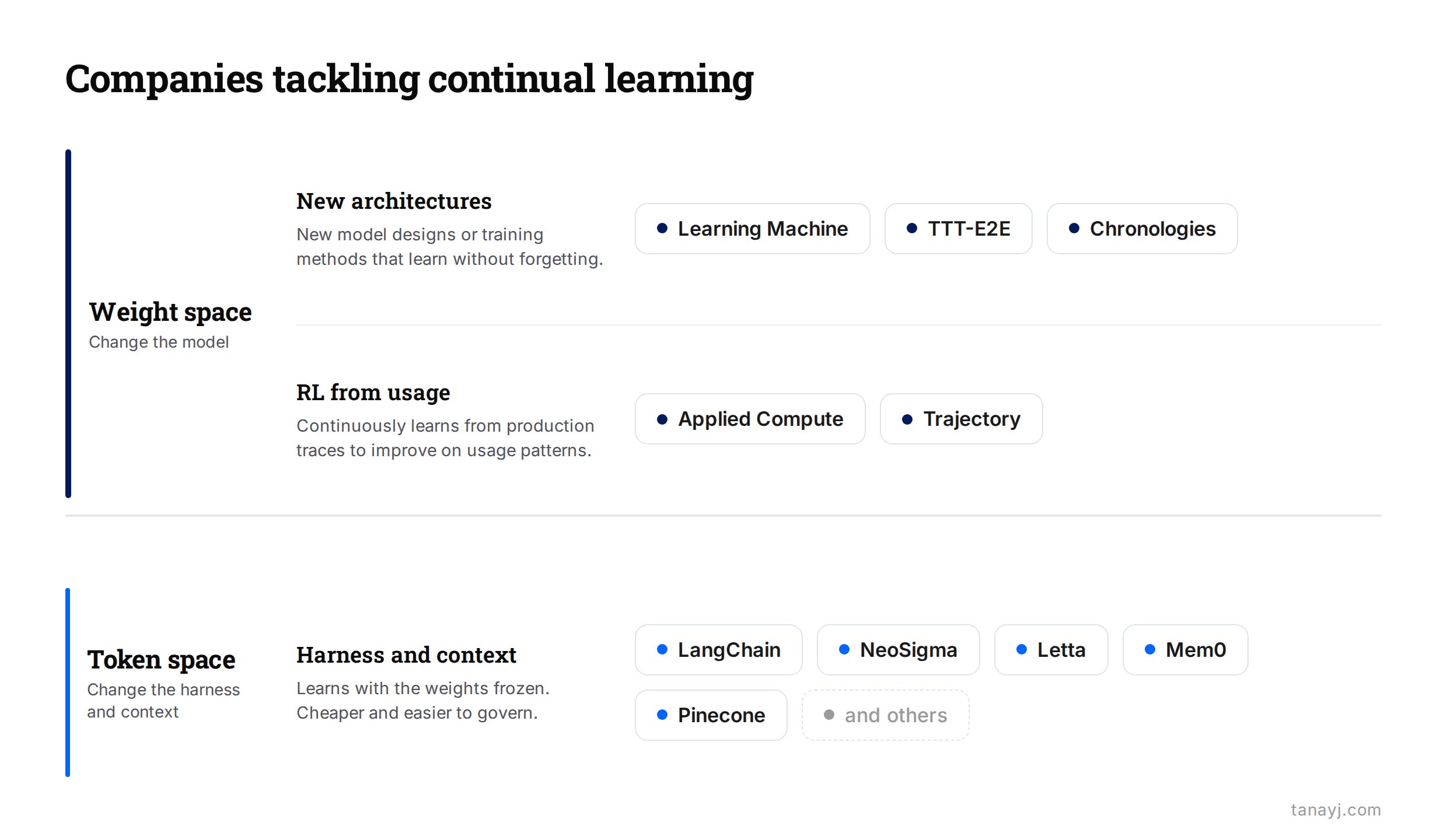
The first camp works at the model level, with new architectures or new ways to update weights that avoid catastrophic forgetting. Some are big architectural bets, others are smaller changes to today’s transformers.
Learning Machine is building models that keep learning during inference, so the model picks up the skill of “how to learn” and adapts to a user or company after it ships.
Chronologies is a lab trying to build models that continuously update without forgetting past information.
TTT-E2E (Stanford and Nvidia) trains a transformer to update its own weights at test time, folding the context it sees into the weights as it goes.
The second camp works with today’s frozen models. They help a company learn from its own production traces, both by post-training the model and by tuning the harness around it. In practice it looks like RL as a service: take the traces, define what good looks like, and use it to update the system. Enough improvements here could mimic a feeling of continual learning.
Applied Compute trains custom agents on a single company’s data and calls it “Specific Intelligence,” a model that improves based on production traces over time.
Trajectory turns production usage into the signal for post-training and bills itself as a complete platform for continual learning.
This is a bit more well understood approach and is what companies like Cursor are already doing. However, at least today, these largely involve one model for the company as opposed to learning on an individual user basis.
The third camp keeps the weights frozen and does the learning in the harness and context (“token space” as discussed earlier). It never touches the model, which is cheaper and easier to govern.
LangChain‘s LangSmith Engine watches production traces, clusters the failures, and proposes harness fixes as pull requests, which is the meta-harness loop as a product.
NeoSigma builds the feedback loop between how a product gets used and the agent running it, suggesting improvements and changes at the harness and context layers.
Companies like Letta, Mem0, Pinecone and others which are around persistent memory that carries across runs help at least improve the system based on context improvements over time.
Closing thoughts
One question around continual learning is whether we’ll have one breakthrough that takes us closer, or if it will be an incremental iterative improvement across all the layers. Already, with techniques like better memory, dreaming, meta-harnesses, the experience has improved significantly. But there’s still a lot more to be done.
In the near term I expect most of the learning to happen in token space, a frozen model with a smarter and smarter wrapper, scoped per company and per user, until from the outside it’s hard to tell the model didn’t actually change. The weight-space version, where the model itself learns from the job and a company’s know-how ends up living in its weights may require more of a breakthrough, but we know all the labs are currently focused on that.
If you’re building in and around continual learning, I’d love to talk. You can reach me at tanay at wing.vc.
Hat tip to Varadh Jain @ Notion for the weight space / token space framing
Permissioning is where this gets hard in regulated finance. A regulator isn't really asking what the model knows, they care which version made a given decision and whether you can roll it back when an update makes things worse. Token space keeps that answerable, you can read the context and the weights aren't shifting under you. Weight space is the stronger version but it leaves you with a model where you can't say which data changed which weights, and on a live system that's the part nobody can answer yet. So for regulated buyers I think it stays in token space for a while, even if the labs crack the rest.