

RL Beyond the Verifiable
RL cracked math and code. The rest of the economy is harder.
I’m Tanay Jaipuria, a partner at Wing and this is a weekly newsletter about the business of the technology industry. To receive Tanay’s Newsletter in your inbox, subscribe here for free:
Hi friends,
On a podcast with Dwarkesh, Dario Amodei, CEO of Anthropic, said he’s 90% sure we get a “country of geniuses in a data center” within ten years. And when he explains the missing 10%, his biggest uncertainty comes down to one thing, the tasks you can’t verify:
With coding, except for that irreducible uncertainty, I think we’ll be there in one or two years. There’s no way we will not be there in ten years in terms of being able to do end-to-end coding. My one little bit of fundamental uncertainty, even on long timescales, is about tasks that aren’t verifiable: planning a mission to Mars; doing some fundamental scientific discovery like CRISPR; writing a novel. It’s hard to verify those tasks.
That’s what we’ll discuss today. In this piece, I’ll cover:
Why verifiability is the constraint
The techniques that are working now
The companies attacking the problem
I. The verifiability constraint
A big reason for the progress over the last year has been RL with verifiable rewards, or RLVR. The idea is simple. Give the model a problem where you can check or verify the answer, let it reason through to a solution, and reinforce the attempts that land on the right one.
Math and code are the perfect fit and we’ve seen the corresponding progress. The reward is clean, cheap, and you can run it millions of times. And the hill-climbing has been real as evidenced by the progress on SWE-bench. In 2025 both OpenAI and Google DeepMind hit gold-medal level at the International Math Olympiad, each scoring 35 out of 42 on problems most strong undergraduates can’t touch.
Jason Wei (then at OpenAI) wrote this up as a “verifier’s law”: the ease of training AI to do a task is roughly proportional to how verifiable the task is. Anything you can check quickly and objectively, you can grind on with RL until it works.
The catch is that most valuable work isn’t necessarily easily verifiable. There’s no test suite for a good memo or a design, let alone for things like building a business, which requires long time horizons and feedback from the real world..
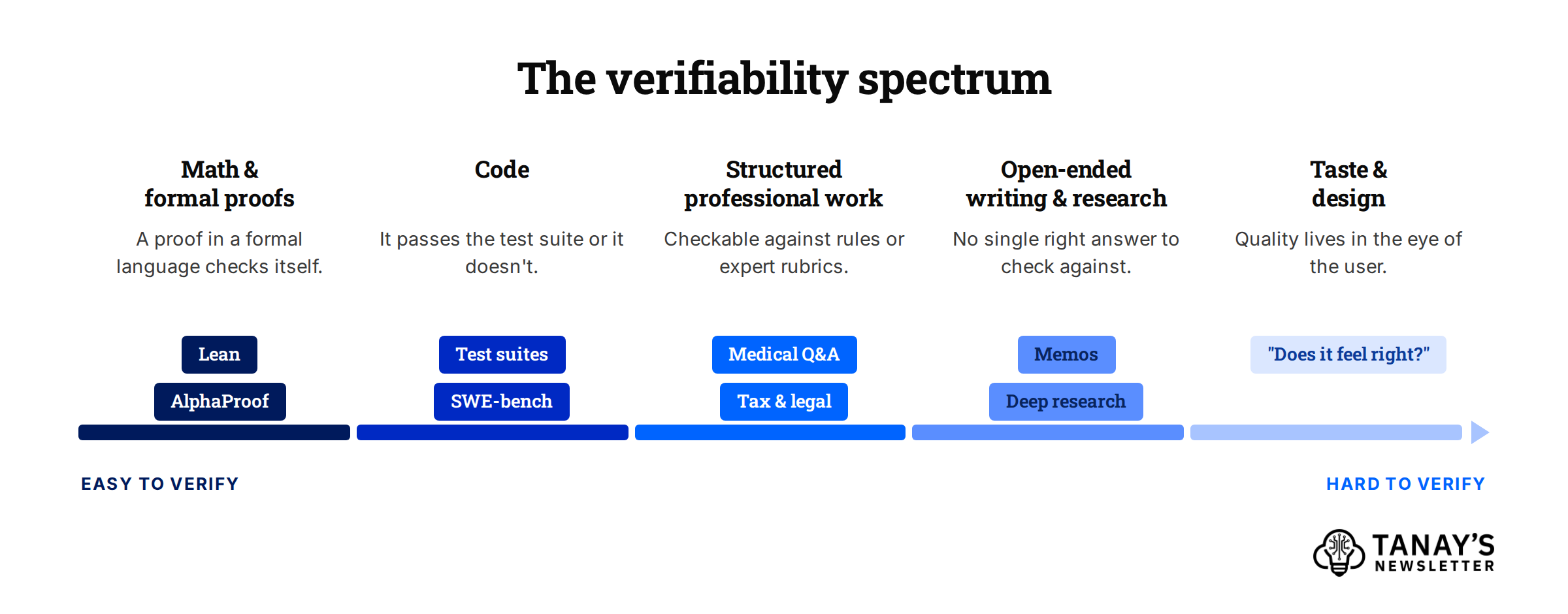
So the whole game in “unverifiable domains” comes down to one question: where does the reward come from when you can’t easily check the answer?
This problem isn’t new. RLHF and Constitutional AI are both, at heart, answers to “what do you do when there’s no checker.”
RLHF trains a separate reward model on human preferences (which of these two answers is better) and then optimizes the model to score well against it. Constitutional AI, which Anthropic uses on every Claude model, swaps much of the human feedback for AI feedback guided by a written set of principles.
These work as forms of alignment but they haven’t produced the capability jumps in subjective domains that RLVR produced in math and code and arguably have optimised for engagement rather than capability improvements. So what are the other ways we can get verifiers or reward signals for subjective domains?
II. The techniques
There are a couple of different approaches being taken to try to verify things that aren’t necessarily easily verifiable:
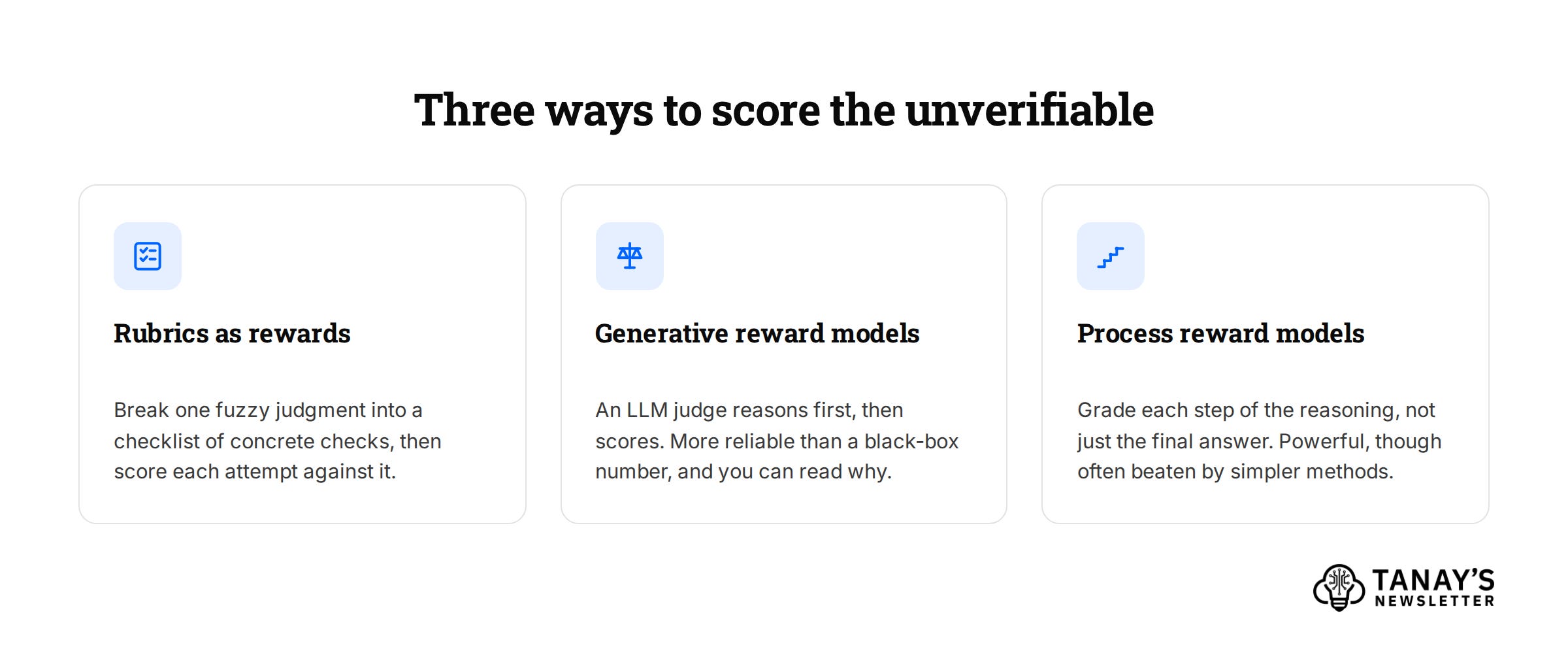
Rubrics as rewards. Scale AI published a paper about this in mid-2025. For each prompt, you generate an instance-specific rubric, a checklist of what a good answer should do, usually anchored to human experts. An LLM judge scores each attempt against the checklist, and that score becomes the reward.
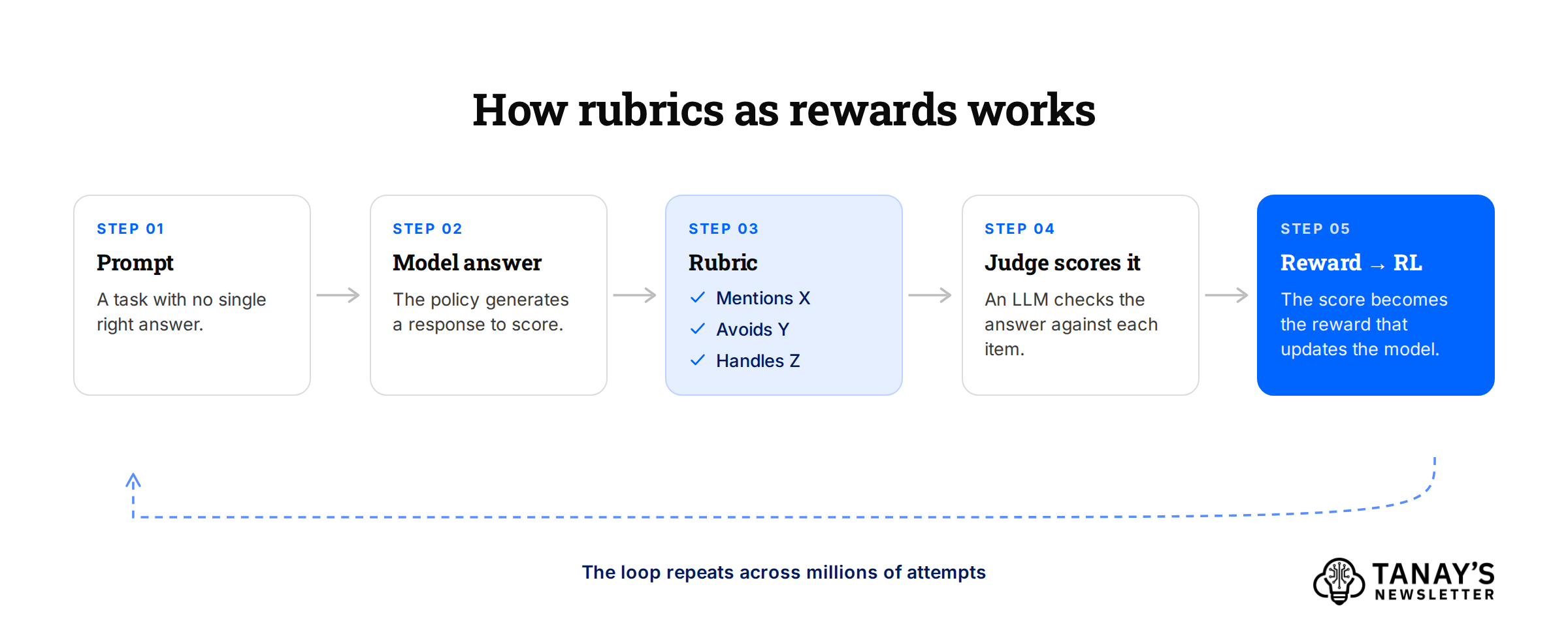
It works because it breaks the question of validating a difficult to verify answer into many smaller yes/no or scoring based questions. Instead of asking a judge “is this good” and getting back a noisy 1-to-10, you ask “does it mention X, avoid Y, handle Z,” and each of those is close to checkable. Scale reported up to a 31% relative gain on HealthBench, a medical benchmark, over plain judge scoring. Follow-up work like OpenRubrics is now focused on generating these rubrics at scale. This is the approach commonly taken by many of the data providers in domains like legal, healthcare, finance, etc.
Generative reward models. This is similar to the LLM-as-judge approach. Instead of spitting out a black-box number, the reward model reasons first and then scores the answer.
Process reward models. This is an approach to grade each step of the reasoning rather than just the final answer, which can be more critical for longer horizon and harder to verify tasks.
The common thread is that when you can’t programmatically create a checker, you can approximate one checker by creating a bunch of rubrics to compare either the final output or intermediate stages, and use LLMs or similar models to grade against those.
III. Companies Tackling This Area
There are a number of companies taking different approaches to try to enable RL in these harder to verify domains:

1. Sell the verifier and the data to labs. The first set of companies are building programmatic verifiers and RL environments in these domains and selling them to the labs. The usual recipe is expert humans writing rubrics for a task, where each rubric item is concrete enough to be checked programmatically, which turns a fuzzy judgment into something you can score at scale. Mercor, Surge, Micro1 and others are doing, this taking the rubics based approach in areas like healthcare, law and finance. Taste Labs is another explicitly going for more subjective areas like design and “taste” that are hard to verify. They explicitly talk about how RLHF stalls because averaging everyone’s preferences leaves you with no taste at all.
2. Formalize the domain. Another approach is to take areas that are somewhat fuzzy and convert them into something a machine can check outright, then sell the end solution in that vertical. In math this already works: a proof written in a formal language like Lean checks itself, which is why systems like DeepMind’s AlphaProof get rewards with no human in the loop.
Pramaana Labs is pushing that idea into messier, higher-stakes work, using formal verification to make answers in regulated fields like tax, law, and healthcare provable. Every domain you manage to formalize leaves the “unverifiable” column.
3. Own the whole loop. Another set of companies focuses on domains where the answer is difficult to verify but can be, just not on a computer. You can’t check a new material or a drug with a rubric or a proof. You have to run the experiment. So these companies own the full loop themselves, AI proposes, a physical lab tests, and the result becomes the reward.
Periodic Labs, started by ex-OpenAI and DeepMind researchers, is running robotic labs to discover new materials. Isomorphic Labs, the DeepMind drug-discovery spinout, grounds its predictions in wet-lab and ultimately clinical reality. Lila Sciences is building autonomous labs across life and materials science. The idea here is that the verification for these systems takes place in the real world and so can be slow and expensive, but by owning the whole loop, you can ground the reward in physical reality.
Closing Thoughts
RL in verifiable areas is clearly working, but the next big leap will come from approaches and companies that help bring the same advancements to the rest of the economy which is harder to verify. And just how far current RLVR approaches generalize, versus whether a new breakthrough is needed, is one of the big open questions. If you’re building in these areas, I’d love to chat!
