

RL and The Era of Experience
On RL scaling, the emerging RL ecosystem and improving agent reliability
I’m Tanay Jaipuria, a partner at Wing and this is a weekly newsletter about the business of the technology industry. To receive Tanay’s Newsletter in your inbox, subscribe here for free:
Hi friends,
Over the last year, we’ve clearly entered a new era where models improve less from static human data and more from real experience. By “experience” I mean these models taking actions in environments, observing outcomes, getting feedback, and then getting better. When you look at what the frontier labs are doing, it increasingly seems like scaling reinforcement learning is how that experience gets converted into improvement.
In this post, I’ll discuss this new paradigm, the emerging stack around it and the open questions at play.
1. The Era of Experience
We were in the “human data” era where models learned from tokens from both the internet and expert data specialists. We trained huge models on massive datasets, and a lot of capabilities emerged from learning over large amounts of language and code.
Now, in the “experience” era, models learn from attempting tasks and receiving feedback in environments that mimic real tasks that we as humans may face. A model is taking a sequence of actions across tools and time.
Silver and Sutton of DeepMind, in their “Era of Experience” paper describe it as: the next generation of agents will learn from streams of interaction, take grounded actions in real action spaces, receive grounded rewards from consequences, and increasingly plan in the currency of experience.
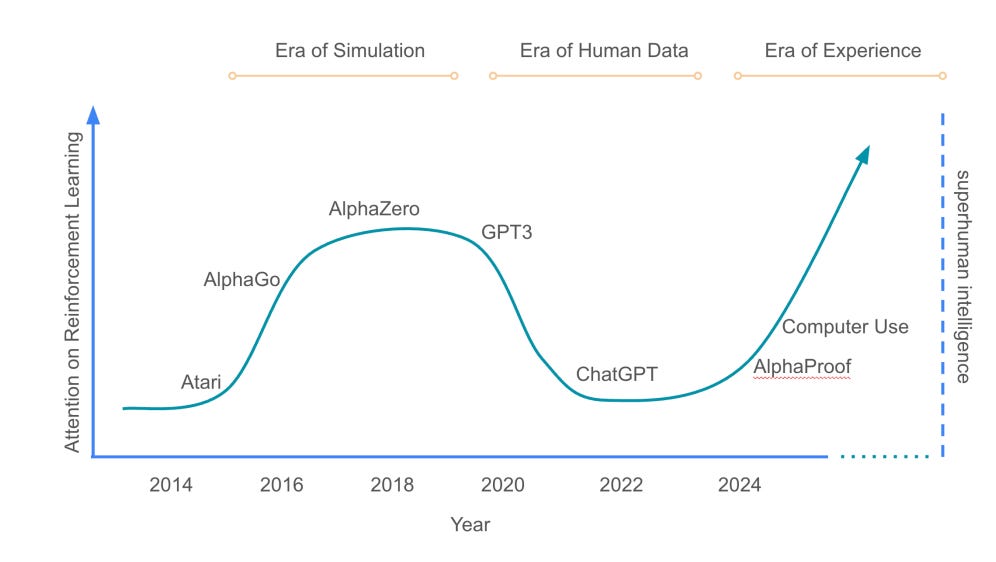
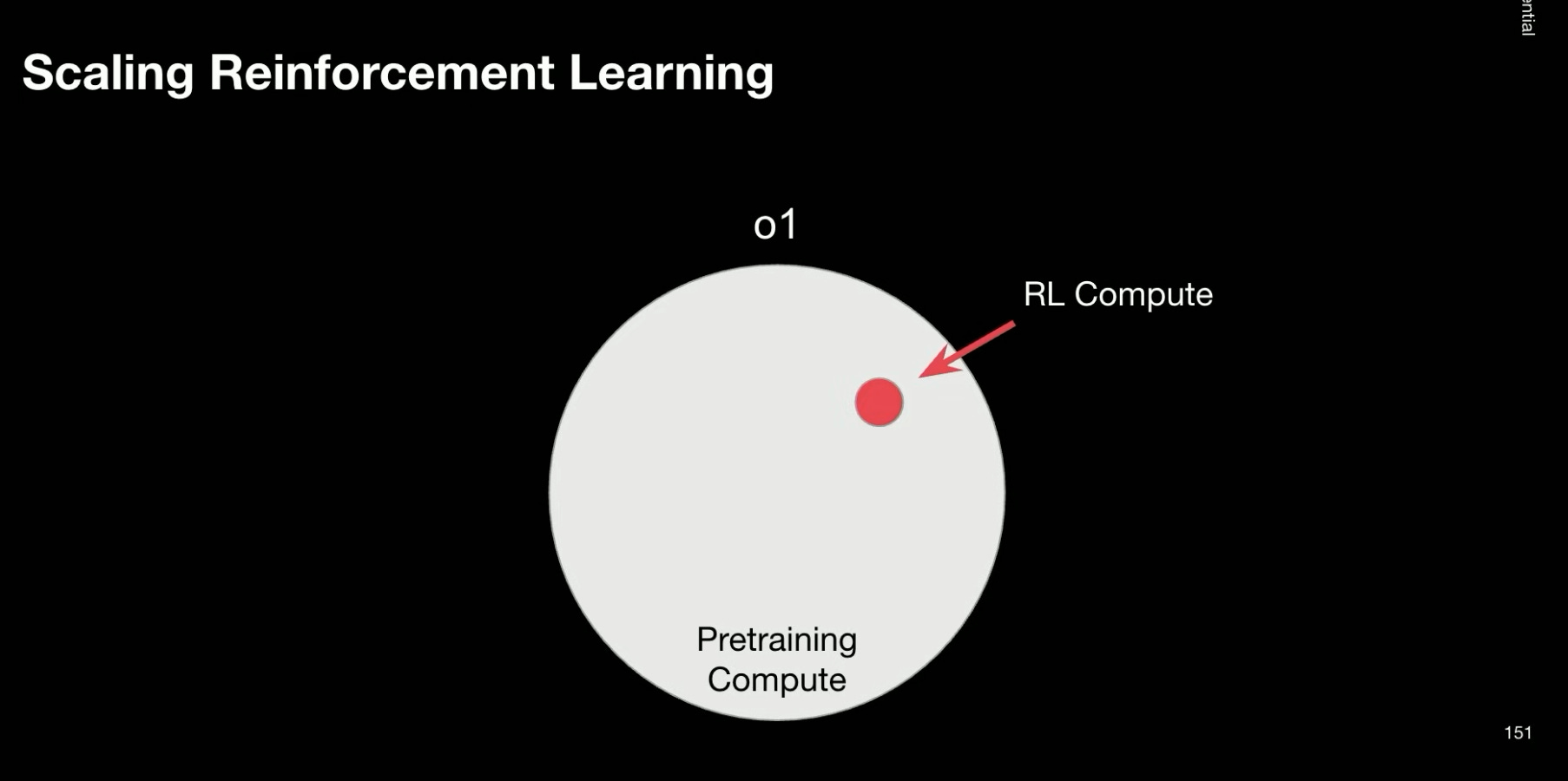
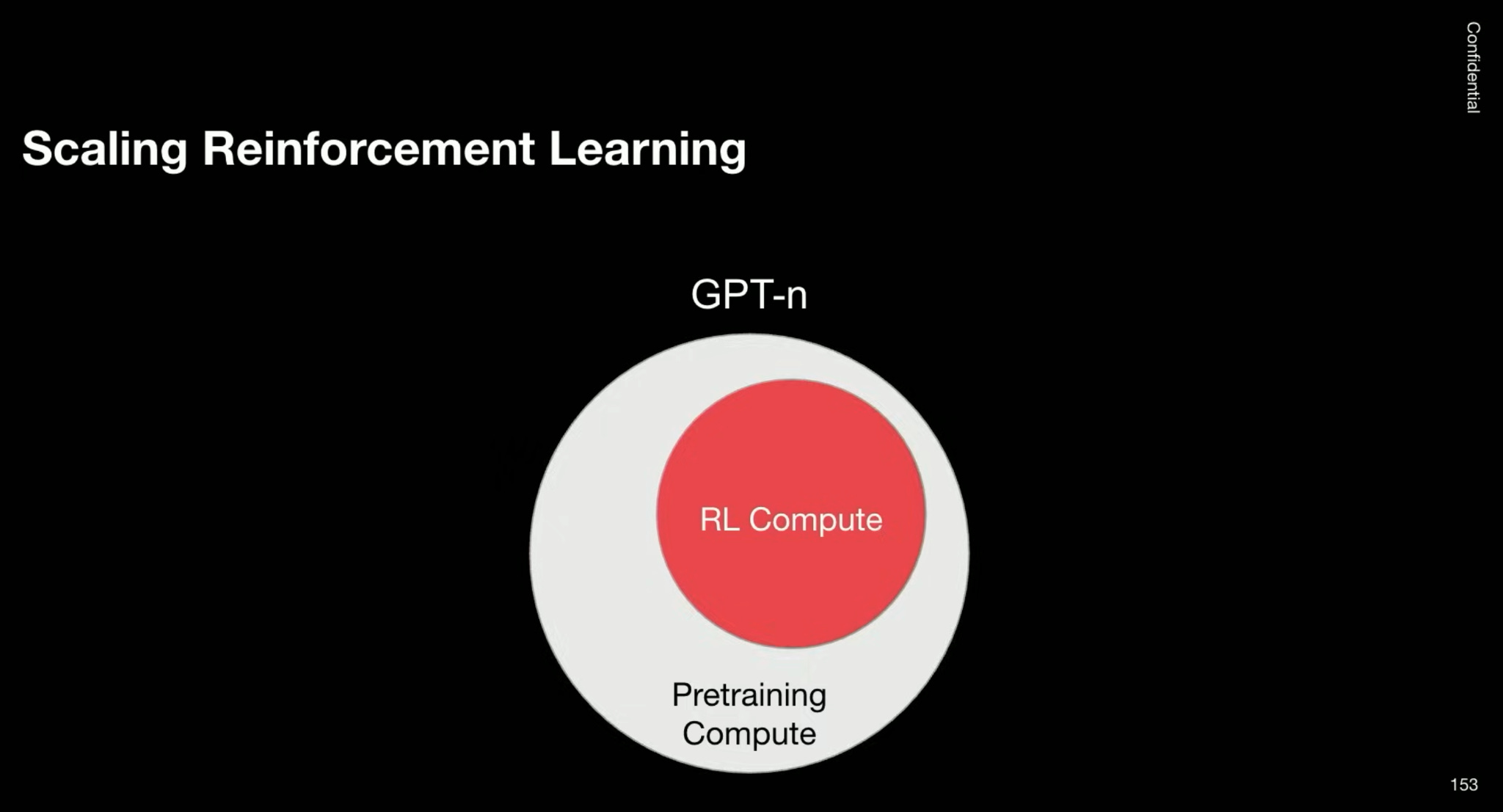
Perhaps the clearest evidence of this is the shift in how labs allocate compute and spend on data. On the compute side, Dan Roberts, an OpenAI researcher, talks about compute going towards RL scaling and talks about a potential world where compute on RL scaling continues to grow to even beyond pre-training.
We added some reinforcement learning compute for o1 … o3 maybe had a little bit more RL compute. At some point in the future maybe we’ll have a lot of RL compute and then at some far point in the future maybe we’ll have just like be totally dominated and crushed by RL compute - Dan Roberts
Similarly, on the data side, the labs have put over dozens of vendors in business in the last year who sell environments to the labs that mimic real world tasks of some form that can be used to improve model performance on these tasks through RL. More on that later in the piece.
Additionally, Brendan Foody, CEO of Mercor notes that RL is getting so good that it can saturate any eval.
RL is becoming so effective that models will be able to saturate any evaluation. This means that the primary barrier to applying agents to the entire economy is building evals for everything. However, AI labs are facing a dire shortage of relevant evaluations. Academic evaluations that labs goal on don’t reflect what consumers and enterprises demand in the economy.
Continued progress through this then hinges on continuing to have new sets of tasks packaged in the right environments that can be used for the models to “play” in and learn from experience in. An environment is the sandbox where the agent can act (100s of thousands of times) and receive feedback (in the form of rewards). In practice, it’s an instrumented version of a real workflow: a UI/application, an API surface or a codebase.
2. The RL “stack”
As RL continues to scale, first inside frontier labs and over time across enterprises and ISVs, a startup ecosystem has formed in a few concrete areas. At a high level, there are three categories of companies: Environment builders (who supply the “data”), RL infrastructure (infrastructure needed to run different RL jobs) and RL-as-a-service (serving those that want more reliable agents but lack the expertise). Let’s go deeper into each!

RL environment builders
These companies supply the form of data that matters for RL, particularly to the labs: environments where agents can take actions, observe outcomes, and get scored.
In practice, an “environment company” usually sells environments packaged as: a workflow surface the agent can act in (UI, API, codebase, toolchain), a task library so you can generate many attempts, an eval that scores the attempts, and logging so you keep full trajectories.
Most of these companies primarily sell to labs today, and tend to have an area of focus although over time will likely expand areas and also potentially sell to enterprises. Common focuses and examples include:
Coding: Preference Model, Proximal, Mechanize
Other forms of specialized knowledge work: Phinity (Chip design), Isidor (finance)
Many of these companies are scaling revenue rapidly, though it’ll be interesting to see which ones can continue to scale and remain flexible and adaptable over time and needs from labs evolve as well as actually provide environments that mimic real-world scenarios at the right level of difficult to drive model performance.
The “incumbent” data vendors to labs such as Turing, Mercor and Surge are also supplying environments, and indeed arguably have the highest share of the market, in addition to traditional forms of human expert data.
RL infrastructure
While the labs may have their own infrastructure built to manage RL, there are a number of companies that have built various forms of infrastructure to make aspects of RL simpler.
Teams that want to run their own RL loops need tooling for rollouts, data collection, evaluation, policy updates, gating, and iteration. They also need the underlying compute and serving stack to keep throughput high.
Startups building in this area include companies building tooling to simplify RL post-train models such as Miles from RadixArk and Tinker from Thinking Machines to all-in-one compute platforms like Prime Intellect or tooling to make building environments themselves easier such as Hud.
RL-as-a-service
There are many enterprises (and software vendors building agents) that have repeatable workflows for which models and agents don’t work out of the box but could benefit use RL.
To serve this group of companies, a number of startups have emerged that are essentially providing RL expertise and outcomes as a service. The pitch is usually: tell us your workflow / success metric, give us your data (agent traces, workflow data) and we will help do the work needed to post-train the model to give you better outcomes.
Most of these startups have built some level of infrastructure and tooling in-house which they pair with FDEs with RL expertise.
Early customers of these companies tend to be AI-native companies that have a core agent in production that they would like to improve. Over time, the same approach can extend to traditional enterprises for all workflows.
Examples of these companies include Applied Compute, Osmosis, and CGFT.
Applications
So far, most RL scaling has happened inside frontier labs. But given the improving infrastructure, I expect that number of companies to grow, and many AI applications that are sitting on real-world trajectories and outcome feedback in a valuable workflow will likely leverage that.
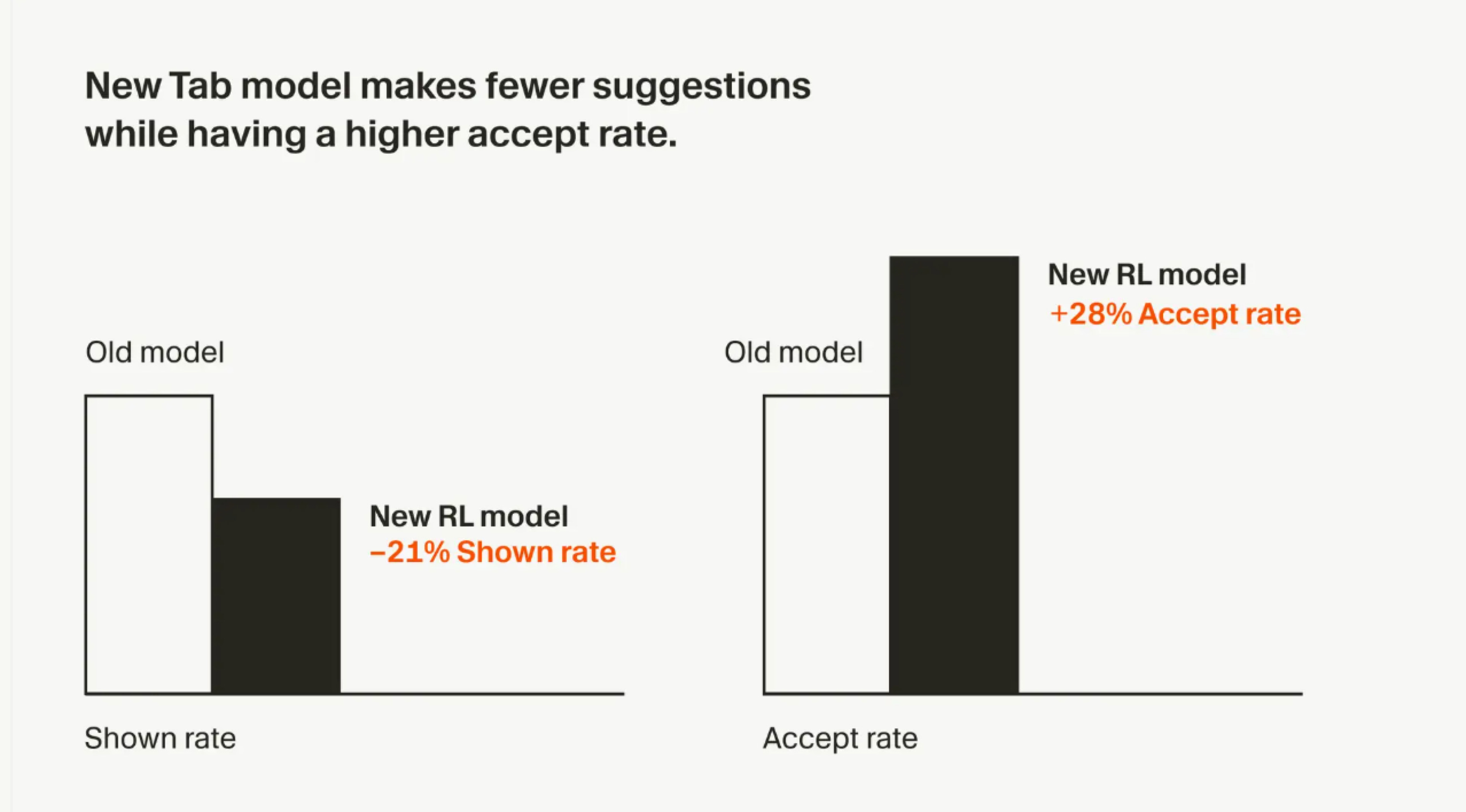
Coding is a great example of an application category with lots of these trajectories given the adoption. Cursor was able to use the feedback from their tab model to train an improved one using online RL, as they describe in this piece. This is how many application companies will actually see the benefit from the data they collect.
3. Closing thoughts
While we have a new vector of scaling that should continue to result in progress over the short to medium term, there are a number of open questions that remain. For one, how well will the models generalize to pick up new “skills” they are explicitly RL’ed on. Ex-OpenAI research lead Jerry Dworek had this to say:
"How do those models generalize? How do those models perform outside of what they've been trained for? ... How do models do tasks that you don't reinforcement learning on? And probably not that great. And this is... basically the remaining questions in the world of AI because what we train for... we are getting really really good at."
The other is around whether RL scaling enough, or do we need more beyond that, with continual learning being the most obvious gap today. Ilya notes that humans are continual learners and whether we need models to do the same:
"Where on the curve of continual learning is it going to be? ...You produce like a superintelligent 15-year-old that’s very eager to go... they don’t know very much at all... and you say 'go and be a programmer, go and be a doctor, go and learn.' So you could imagine that the deployment itself will involve some kind of a learning trial and error period. It’s a process as opposed to you drop the finished thing."
Regardless of whether RL takes us to AGI however, it’s clearly driving model improvement, and a fruitful area for companies to both build in in the infrastructure area and application companies to leverage over time. If you’re building anywhere in this stack, I’d love to hear from you.