

AI and the decline of the Open Web
This is a weekly newsletter about the business of the technology industry. To receive Tanay’s Newsletter in your inbox, subscribe here for free:
Hi friends,
One of the key characteristics of the web has been that it is open. While some of the core tenets of openness: interoperability (open standards), accessibility (use any hardware/software), and freedom of speech (anybody can put up a website) are still true, one aspect of openness that I’ve always found important is around a large amount of the internet being available without paywalls or logins and findable and accessible using search engines.
But over the years we’ve been retreating towards a less “open” internet, as I’ll discuss below, and AI might be the final straw.

I. Mobile and Login-walls
Even prior to AI, with the wave towards mobile, many companies realized that users retain better if i) logged in and ii) have a mobile app installed, since both of these means that they can be sent emails and push notifications among other things.
This meant that many user-generated content companies, such as Glassdoor, Tripadvisor, TikTok, Quora, and others, required users to log in or download their mobile app to continue scrolling beyond a certain point. Their content was still indexable by search engines, but the resulting page was often covered in a wall such as below.
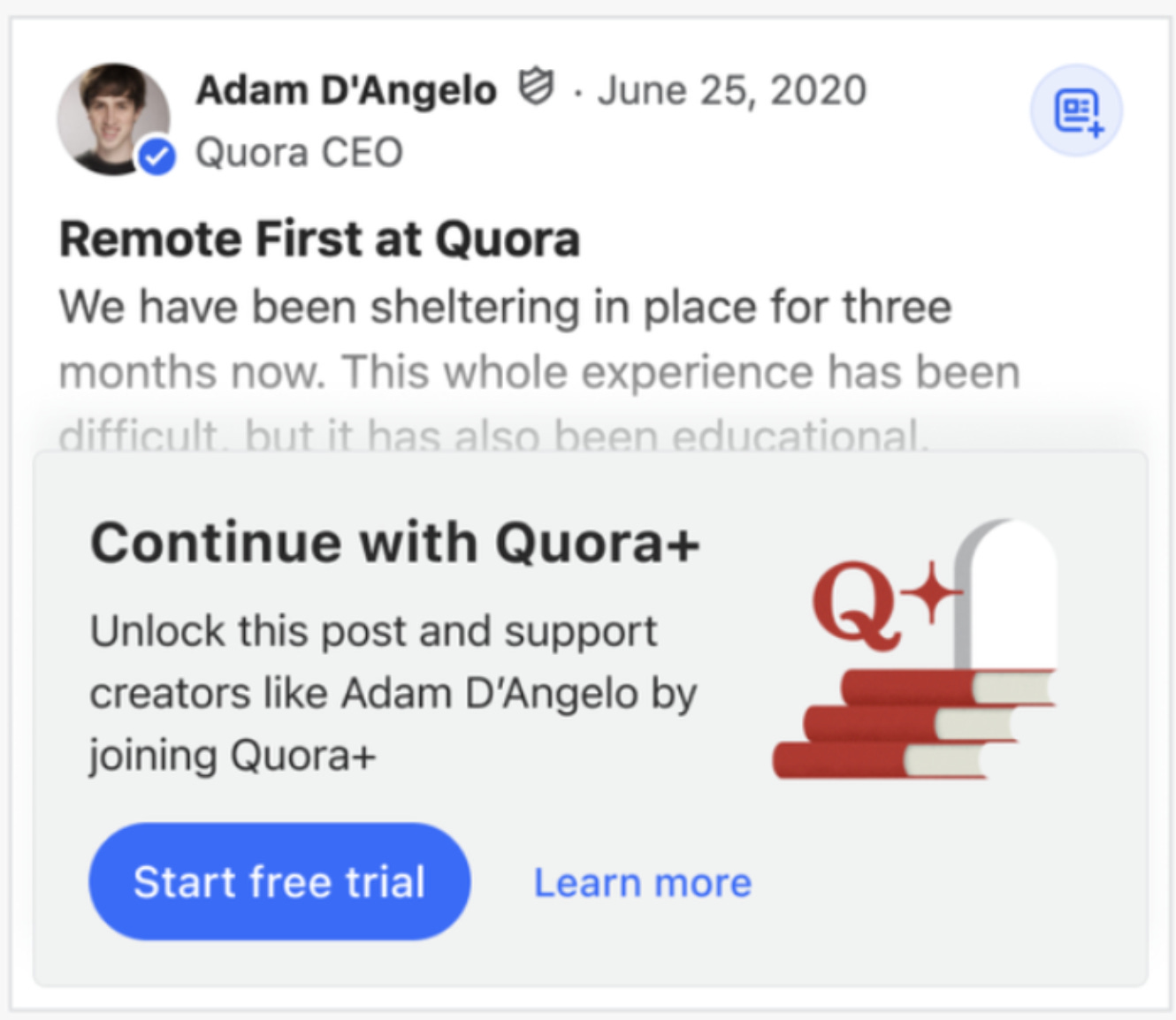
With the rise of AI, its possible that some may take even more drastic action and block the indexing of their content fully.
II. Forums → “Private” Communities
In the early days of "web2", there were a number of bustling forums on the internet where communities had discussions over shared interests. The idea of communities has only grown, but they’ve moved from forums to places like Discord and Slack, or even to large group chats on WhatsApp and Telegram.

Some of these are private by their design and nature based on their nature. But even the ones that are public and in theory open to all are generally missing one crucial thing: they are no longer indexable or searchable, and the content within it is largely gatekept to those in the community, in contrast with the days of the forum.
And with the growing importance of proprietary data and content, it's likely that platforms like Discord and Slack will want to shore up their data assets or at least be able to monetize their use in AI models
III. AI and The Rise of Walled Gardens
While some platforms, such as Facebook or Snap, tended to be walled gardens at the outset due to the privacy limitations of the posts on them, we've been seeing a trend towards an increase in walled gardens, even by platforms that were generally public.
This has in particular been driven by the recent increase in training of LLMs and the importance of these data sources in them.
One example is Reddit. Last month, Reddit raised its API prices, making many third-party clients untenable. In protest, as many as ~7,800 of the tracked ~10,000 key subreddits went dark. Even today, about 1,500 of them are dark.

In their search for profits, Reddit is trying to better monetize their data as AI models seek to use it, and also ensure that their app (on which they can show ads) gains users over third-party ones. They have also increasingly restricted browsing for users who are not logged in, especially on mobile phones.
Similarly, Twitter, where most accounts are public and most tweets have been publicly accessible, recently has made a number of moves towards going more "closed," largely in order to monetize its data and user base in a world where many AI models want to train on its data.
They raised the prices of their APIs, which forced many services that either read or wrote to Twitter to be unable to continue to do so.
They also removed the public viewing of tweets for non-logged-in users. Users are now redirected to a login page. This also broke the ability of tweets to be embedded in places like iMessage, though Twitter then flip-flopped on that.
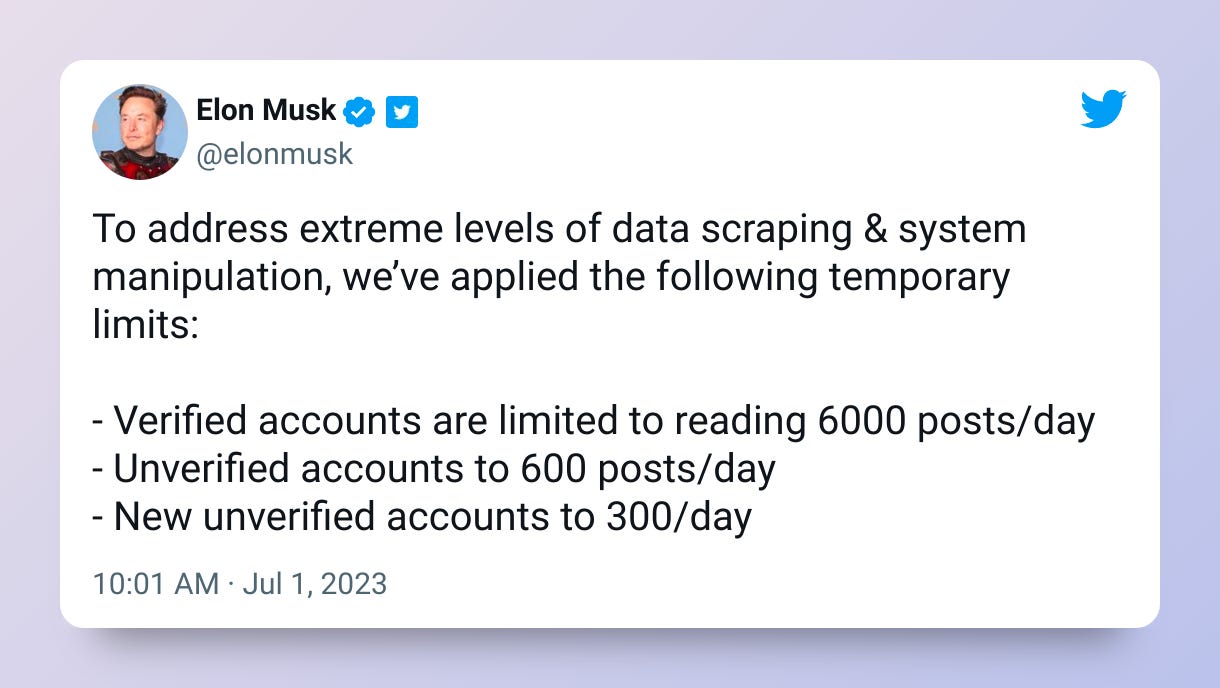
They imposed rate limits on users, both free users and Twitter blue users (who had a higher rate limit). While skeptics saw this as another in a series of moves to encourage paying for Twitter Blue, Elon Musk said it was in part driven by large amounts of scraping taking places.
IV. Content for machines over humans
While not directly against the open web, Generative AI and LLMs reduce the cost of content creation to close to zero, and we're in the early innings of an explosion of AI-generated content specifically made to rank highly in search engines to get traffic.
Some of this content may be useful, but a lot of it won’t, and it will just make it harder to find the more useful content that actually answers the searcher’s query.
Just having content accessible in theory isn't enough if nobody can actually find or access them, and so in this way, the explosion of AI-generated content to "exploit" search engines could also further harm the open web
On this point, however, it is possible that chatbots and LLMs will fill that gap if search quality declines.
So what do you think? Is the open web dead? Let me know your thoughts! Next week I’ll touch on the other side of this topic: what might save the open web.
If you liked this post, give it a heart up above to help others find it or share it with your friends.
If you have any comments or thoughts, feel free to tweet at me.
If you’re not a subscriber, you can subscribe for free below. I write about things related to technology and business once a week on Mondays.
Basically there are two sides to this story
a) the generation/supply of Foundational Models
b) the demand/usage of these models
Thanks to 'a', we may start seeing the kind of data scraping that we never saw before and would definitely see new measures/policies by platforms.
However as you rightly pointed out, over the years we have already gravitated towards paywalled content and private communities. So the change that could happen because of more and more training of such models would be incremental and slow
Also at least for the foreseeable future, the rate at which generation of these models will happen will be much lower than the rate at which these models will be used to create content. So the impact of AI at least in the foreseeable future might be more on "Relevance of Web" than on "Openness of Web".